First of several videos from David Weinberger capturing some of the proceedings from the Summit. Thanks David, and all the interviewees!
Month: June 2011
Proposed: a 4-star classification-scheme for linked open cultural metadata
One of the outcomes of last week’s LOD-LAM Summit was a draft document proposing a new way to assess the openness/usefulness of linked data for the LAM community. This is a work in progress, but is already provoking interesting debate on our options as we try to create a shared strategy. Here’s what the document looks like today, and we welcome your comments, questions and feedback as we work towards version 1.0.
*******************************************************************
DRAFT
A 4 star classification-scheme for linked open cultural metadata
Publishing openly licensed data on the Web and contributing to the Linked Open Data ecosystem can have a number of benefits for libraries, archives and museums.
- Driving users to your online content (e.g., by improved search engine optimization);
- Enabling new scholarship that can only be done with open data;
- Allowing the creation of new services for discovery;
- Stimulating collaboration in the library, archives and museums world and beyond.
In order to achieve these benefits libraries, museums and archives are faced with decisions about releasing their metadata under various open terms. To be open and useful as linked data requires deliberate design choices and systems must be built from the beginning with openness and utility in mind. To be useful for third parties, all metadata made available online must be published under a clear rights statement.
This 4-star classification system arranges those rights statements (e.g. licenses or waivers) that comply with the relevant conditions (2-11) of the open knowledge definition (version 1.1) by order of openness and usefulness: the more stars the more open and easier the metadata is to used in a linked data context. Libraries, archives and museums wanting to contribute to the Linked Open Data ecosystem should strive to make their metadata available under the most open instrument that they are comfortable with that maximizes the data’s usefulness to the community..
Note: This system assumes that libraries, archives and museums have the required rights over the metadata to make it available under the waivers and licenses listed below. If the metadata you want to make available includes external data (for example vocabularies) you may be constrained by contract or copyright to release the data under one of the licenses below.
★★★★ Public Domain (CC0 / ODC PDDL / Public Domain Mark)
as a user:
- metadata can be used by anyone for any purpose
- permission to use the metadata is not contingent on anything
- metadata can be combined with any other metadata set (including closed metadata sets)
as a provider:
- you are waiving all rights over your metadata so it can be most easily reused
- you can specify whether and how you would like acknowledgement (attribution or citation, and by what mechanism) from users of your metadata, but it will not be legally binding
This option is considered best since it requires the least action by the user to reuse the data, and to link or integrate the data with other data. It supports the creation of new services by both non-commercial and commercial parties (e.g. search engines), encourages innovation, and maximizes the value of the library, archive or museum’s investment in creating the metadata.
★★★ Attribution License (CC-BY / ODC-BY) when the licensor considers linkbacks to meet the attribution requirement
as a user:
- metadata can be used by anyone for any purpose
- permission to use the metadata is contingent on providing attribution by linkback to the data source
- metadata can be combined with any other metadata set, including closed metadata sets, as long as the attribution link is retained
as a provider:
- you get attribution whenever your data is used
This option meets the definition of openness, but constrains the user of the data by requiring them to provide attribution (in the legal sense, which is not the same as citation in the scholarly sense). Here, attribution is satisfied by a simple, standard Web mechanism from the new data product or service. By using standard practice such as a linkback, attribution is satisfied without requiring the user to discover which attribution method is required and how to implement it for each dataset reused. Note that there are other methods of satisfying a legal attribution requirement (see below) but here we propose a specific mechanism that would minimize the effort needed to use the data if the LAM community collectively agrees to it. Also note that even this simple (ideally shared) attribution method could prevent some applications of linked data if linkbacks are required by many datasets from many sources.
★★ Attribution License (CC-BY / ODC-BY) with another form of attribution
as a user:
- metadata can be used by anyone for any purpose
- permission to use the metadata is contingent on providing attribution in a way specified by the provider
- metadata can be combined with any other metadata set (including closed metadata sets)
as a data provider:
- you get attribution whenever your data is used by the method you specify
This option meets the definition of openness in the same way as the linkback attribution open, but requires the user to provide attribution is some way other than a linkback, as specified by the data provider. The provider could specify an equally simple mechanism (e.g. by retention of another field, such as ‘creator’ from the original metadata record) or by a more complex mechanism (e.g. a scholarly citation in a Web page connected to the new data product or service). The disadvantage of this option is that the user must discover what mechanism is wanted by the particular data provider and how to comply with it, potentially needing a different mechanism for each dataset reused. For large-scale open data integration (e.g. mashups) this option is difficult to implement.
★ Attribution Share-Alike License (CC-BY-SA/ODC-ODbL)
as a user:
- metadata can be used by anyone for any purpose
- permission to use the metadata is contingent on providing attribution in a way specified by the provider
- metadata can only be combined with data that allows re-distributions under the terms of this license
as a provider:
- you get attribution whenever your data is used
- you only allow use of your data by entities that also make make their data available for open reuse under exactly the same license
This option meets the definition of openness but potentially limits reuse of data since if more than one dataset is reused and if each dataset has an associated Share-Alike license. Under an Share-Alike license, the only way to legally combine two datasets is if they share exactly the same SA license, since most SA licenses require that reused data be redistributed under exactly same license. If the source datasets had different Share-Alike licenses originally (e.g. CC-BY-SA and ODC-ODbl) then there is no way for the user to comply with the requirements of both source data licenses so this option only allows users to link or integrate data distributed under one particular SA license (or one SA license and any of the other license or waiver options above). In the LAM domain, where significant value is created by combining datasets, the Share-Alike license requirement severely reduces the utility of a dataset.
Related Material
Users, uses, service
Yesterday at LOD-LAM we talked about users and what users might want to do with data (and thus what we could create for users from LOD). Here’s the mind map of that:
user verbs
{kind=link}
Library Linked Data cloud – a teaser
Following up on this afternoon’s dork shorts, with Tom Baker presenting W3C’s Library Linked Data incubator, and Adrian Pohl telling us about the really useful ckan.net, here’s a graphical rendering of library linked datasets on the CKAN LLD group, courtesy of William Waites:
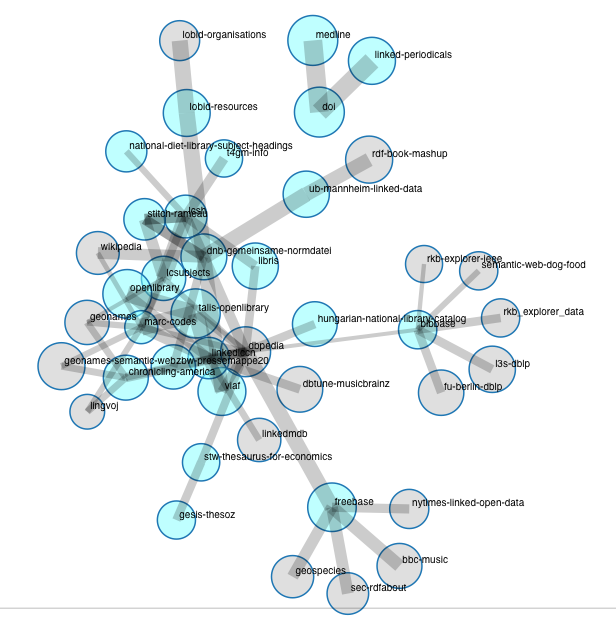
We plan to keep updating and use this in one of our incubator’s deliverables (draft in progress here, comments welcome as for the main LLD report draft). The idea is to get something closer to our community than the ever growing general LOD cloud.
So, we’ve got a start for the “L” in LAM. But where are As and Ms? C’mon!!!
I guess augmenting such a library graph with the published datasets from museums and archives could be a first work item for a W3C community group on LOD-LAM…
Beyond OAI-PMH Report
Thanks to everyone who participated in the Beyond OAI-PMH session this morning. There seems to be a number of places where others have posted their session summaries, but I thought it would be useful to include that here on the LOD-LAM site as well.
This is my brief (and somewhat tardy) account of our meeting based on the notes that I jotted down. Comments and responses are welcome and any misrepresentations are my own.
Two main themes:
1. We need to leverage existing OAI-PMH installation base for Linked Data, because after all it does fit within the basic requirements (three stars) of Linked Data goals.
- Promote adoption of tools like OAI2LOD server
- Build Sitemaps using existing OAI services
We should acknowledge current OAI-PMH for their existing contributions to Linked Open Data and emphasize that they already are participating in LOD through OAI-PMH. While there are some additional things we can do to make the metadata we share more LOD friendly, LOD is not a completely new idea. Additional documentation about how OAI-PMH has succeed and failed – and what lessons that holds for the future of LOD – would be welcome.
2. We don’t necessarily need an OAI-PMH 3.0
It would be better for the community to look towards broadly adopted web standards. Repositories need to provide what users want in multiple serializations, not limited to XML (let alone a specific XML schema).
Some suggestions for alternatives:
- Sitemaps
- Open Search
- Atom
While there wasn’t a strong sense that a new OAI standard was needed, there is a recognized need to provide the existing repositories some guidance about alternative approaches. Such guidance should be promoted by funders to help new and existing projects understand how they can contrbute to the Linked Data cloud. There was also a sense that some features of the current OAI protocal might be included in the development of web services:
- ability to acquire incremental sets (what’s changed, what’s new)
- an understanding of the “scope” of what’s provided (OAI sets/collections)
- a minimal set of shared properties (a stub) that is linked directly to richer representations
- some consensus around shared service models to make discovery and use easier
- ability to request sets based on supplied criteria (“search” not just pre-constructed sets)
Of course the devil is in the details, during the session we had several tangential conversations about the technical details of how to implement some of these alternatives that I haven’t fully captured here. To me this indicates that further discussion about these different options and how they might be shaped into a common framework is needed and would be valuable guidance for the community.
Additional Comment
There was also a suggestion that OAI-PMH may still be the best way to share large sets of “records” between partners. Rather than worry about making OAI-PMH more LOD friendly, LAMs may wish to focus their energy on providing other kinds of data as LOD (use cases?)
From #elag2011 to #lodlam
Prior to the LOD-LAM summit, ELAG2011 took place in the impressive Czech National Technical Library in Prague from 24th to 27th of May under the slogan “It’s the context, stupid!”. ‘ELAG’ stands for “European Library Automation Group” which is an annually meeting of technicians from the European library world plus some international participants. This conference stands out from other gatherings of librarians: It is attended by a lot of technical staff or other practitioners.
There is no formally elected ELAG planning group, anyone can join in and participate in the organization of ELAG. This grassroots approach combined with the attendees’ hands-on attitude guarentees most of the time really exciting workshops and presentations. Also, marketing language is frowned upon by the practitioners which attend ELAG (just take a look at the tweets to get an impression). Consequently, the sponsorship is only promoted decently and no products are presented along the way. The perfect basis for a great conference!
Giving LOD its place
Obviously ELAG 2011 was a good preparation for the LOD-LAM summit and I hope that the discussions that took place and the topics that were discussed at ELAG 2011 will be picked up at the summit. Linked Open Data played a central role during the whole ELAG conference. According to the program, there were at least eight of fifteen presentations, one of four pre-conference bootcamps and two of ten workshops which obviously had Linked (Open) Data as subject.
I offered two activities on LOD at ELAG which also may be topic at the LOD-LAM summit:In a bootcamp during pre-conference – mainly led by my colleague Felix Ostrowski – people learned how to enrich webpages providing information about one’s organization with RDFa to make the institution part of the Linked Data web. I also led a small workshop that dealt with open data licensing issues. People interested in opening up their institution’s data discussed the problems they encountered as well as strategies to cope with them. (BTW, I started a list of projects using or publishing open bibliographic data for this workshop. I am happy about hints to relevant projects that aren’t listed there.)
Pushing the vendors
“We, the participants of ELAG 2011, holds these truths to be self-evident, that MARC must die, and that Linked Open Data is the future.”
With these words Anders Söderbäck in his presentation “Who controls bibliographic control?” tried to capture the spirit of ELAG2011 and to draw the attention of two big library system vendors to the topic of LOD.
Preceding Anders’ post in the session on cloud computing, represantatives of OCLC and ExLibris had the opportunity to talk about their companies’ future cloud-based library management systems. While Paul Harvey from OCLC held the usual OCLC presentation about the company’s Webscale Management System (in development), Carl Grant didn’t talk too much about ExLibris corresponding product Alma (also in development) but about his general approach to cloud computing.
How about web integration of library data in future systems?
Being directly asked by Till Kinstler what both companies do to integrate their systems into the web, none of the vendor representatives managed to actually provide an answer. To me it looks like OCLC and Ex Libris started one or two years too early with buidling their new cloud-based systems and now – understandably – have problems to adjust to the looming fundamental changes to cataloging, data formats and data licensing in the library world.
Open WorldCat?
Some news during ELAG2011 made it seem that at least OCLC moves into the right direction. A blog post by John Mark Ockerbloom brought the good news on the licensing aspect, pointing to OCLC’s strategy change to investigate open licensing and allowing or even encouraging the publication of Open Data by member institutions. Hopefully, OCLC will further pursue this path.
Be consequent!
For me, the most significant insight at ELAG2011 was how important for single institutions as well as for the whole community a consequent approach in adopting LOD is. By now, most of the active institutions are experimenting with this new technology, playing around with Linked Data best practices. But as most libraries are closely tight to a vendor they also make their future development more or less dependening on the products that will be offered by this vendor.
To really pursue a consistent strategy one has to make clear: We really want LOD and we will only invest into future products which really support the LOD best practices! In case vendors won’t comply with this, it may be time to cooperatively build appropriate Open Source technology…